 ERMProtect is Partnering with NimbusDDOS to Expand DDoS Resilience Testing Services
ERMProtect is Partnering with NimbusDDOS to Expand DDoS Resilience Testing ServicesOne in a Series of Articles About Auditing Agentic AI Systems
AI agents and autonomous AI are topics on everyone’s mind right now — and for good reason. These tools are equal parts exciting and unsettling. On one hand, they can take on the daunting, draining, time-consuming work tasks that eat up our days. On the other hand, they’re the fuel behind every “AI is taking over the world” conversation — and those conversations aren’t entirely unfounded.
An AI agent is a system that perceives its environment, reasons about goals defined in natural language, plans a sequence of steps, selects external tools, and autonomously executes actions to achieve those goals.
Unlike a traditional chatbot, which waits for a prompt, responds, and never acts, or a standard automation that runs predefined scripts but never truly decides anything, an AI agent perceives, reasons, and acts in real time, directly on real business systems.
Understanding how agents think and act isn’t just a technical exercise – it is the foundation for knowing where controls can break down – essential information for anyone assigned to audit the security and compliance of an agentic AI system.
The Perception → Reasoning → Action Cycle
Like the human mind, agentic AI thinks and acts through a continuous loop: gather information, analyze it, execute. This “thought process” is exactly what makes an AI agent so capable — and so risky. At each stage of that process, distinct threats emerge.
It starts with perception, where the agent takes inputs from its environment, including user prompts, documents, emails, web content, APIs, and memory. The danger here is indirect prompt injection, or malicious instructions hidden inside external data that the agent reads and unknowingly acts on.
Next comes reasoning, where the LLM interprets context, maps out steps, and decides which tools to use and how. This is where hallucinations, bias, and a lack of explainability become real problems, as the agent may make a decision no one can fully reconstruct or justify after the fact.
Finally, there’s action, where the agent stops thinking and starts doing. It sends emails, modifies records, executes transactions, and deploys code. The biggest risk in this stage is that unauthorized actions and privilege escalation can happen faster than human reviewers can catch them.
The bottom line for auditors is this: the risk is no longer just in who can access the model. It lies in what the model decides to do once it has that access.

The Evolution from LLM to Agentic AI
The best way to understand how AI has evolved to become agentic is through an analogy we already know: the human body.
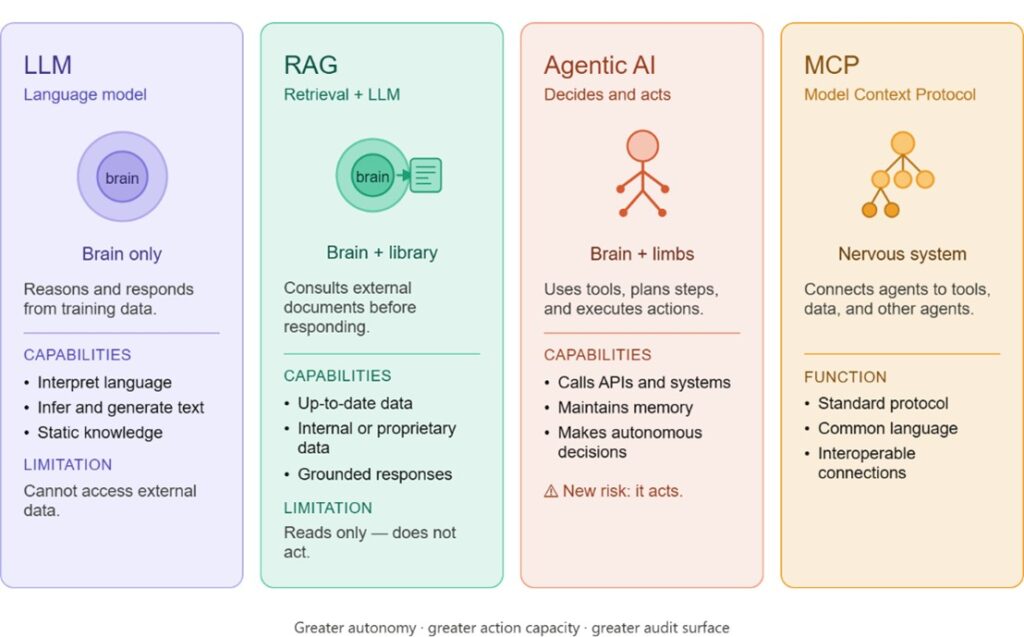
A standalone LLM is like a brain. It interprets information, reasons, and responds, but only from what it already knows. Its knowledge is frozen at the moment it was trained. Add RAG, (Retrieval Augmented Generation) and you have a brain with a library. The reasoning works the same way, but now it can consult external documents before responding, pulling in information beyond its training data.
Agentic AI gives that brain a body. Agents use tools, maintain memory, and take autonomous actions in the world. They are no longer just thinking, they are doing. And MCP — the Model Context Protocol — is the nervous system. This is the infrastructure that connects the agent to its tools, its data sources, and other agents, allowing signals to flow seamlessly between them.
Each step in this evolution represents a meaningful leap in capability. But it also represents a meaningful leap in risk. Greater autonomy means greater action capacity, which means a larger, more complex audit surface.
For auditors, the scope of what needs to be examined, tested, and controlled grows with every capability you add. You’re no longer just reviewing what the system knows. You’re reviewing what it can do, what it decides to do, and whether anyone is watching when it does it.
Inside an Agentic Architecture
An agentic AI system is made up of eight distinct components. Each one is its own attack surface. Each one is its own control point. And each one deserves its own line of audit inquiry.
Model (LLM) — This is the reasoning core. It interprets context, forms plans, and decides what actions to take. For auditors, the key questions are: which model is being used, what version, who approved it, and how is its behavior validated before and after deployment?
Memory — Agents don’t just process one prompt and move on. They maintain short-term memory within a conversation and long-term memory in vector stores that persist across sessions. That stored memory can be manipulated, poisoned, or simply never reviewed. Auditors should ask: what gets written to memory, who can read it, and how long does it last?
Tools — This is where the agent stops thinking and starts acting. Tools are the APIs, plugins, and connectors that allow the agent to interact with real systems, sending emails, querying databases, executing code. Every tool is a potential point of unauthorized action. Auditors need a complete inventory of approved tools, and evidence that unapproved ones are blocked.
Context Data — Before the agent responds, it’s often fed documents, user profiles, or retrieved content via RAG. That injected context shapes every decision the agent makes. If it’s tampered with or poorly controlled, the agent acts on bad information — and may never know it. Auditors should examine what data sources feed the prompt, how they’re validated, and who controls them.
Orchestrator — In multi-agent systems, an orchestrator coordinates the flow, directing which agents run, in what order, with what inputs. It’s also where guardrails are typically defined. Because it sits above everything else, it’s a high-value target. A compromised or misconfigured orchestrator can undermine every control downstream.
Guardrails — These are the filters, validators, and policies that govern what goes in and what comes out. They’re the agent’s seatbelt. But like any control, they can be misconfigured, bypassed, or simply absent. Auditors should verify that guardrails exist, that they’re actually enforced, and that someone is reviewing whether they’re holding.
Identity — When an agent calls a downstream system, it authenticates as someone or something. If that identity is shared, over-privileged, or poorly managed, the agent can access far more than it should. Auditors should treat agent identities with the same scrutiny as privileged human accounts: least privilege, regular review, and clear ownership.
Observability — If you can’t see what the agent decided, what context it used, and what tools it called, you cannot audit it. Observability infrastructure — the capture of prompts, reasoning traces, and tool calls — is not a nice-to-have. It’s the evidentiary foundation of the entire audit. Auditors should verify not just that logs exist, but that they’re complete, immutable, and retained long enough to be useful.
Each of these eight components have a distinct attack surface. Auditing only “the model” leaves out 80% of the risk. The real exposure lives in how these components connect, what permissions they carry, and whether anyone is watching them work.
Three Deployment Patterns
Not all agentic AI systems are built the same way. An auditor’s first question when approaching any AI system should be: how is this structured? The architecture says a lot about where the risk concentrates, how traceable decisions are, and how hard governance will be.
There are three most common patterns, and each comes with its own set of trade-offs.
Single agent — This is the simplest architecture, where one agent receives, plans, and executes. It is simple to govern but also concentrates all the risk. There’s a clear owner, a single decision-maker, and a relatively contained audit scope. At the same time, all risk — and all failure — lives in one system.
Multiple agents — With multiple agents, the work is divided. One agent analyzes, one decides, another executes. Each agent is specialized for its role, which tends to produce better outputs and allows the system to scale in ways a single agent can’t.
But specialization introduces complexity. Decisions get distributed and so does accountability, and tracing a problematic output back to the decision point that caused it becomes difficult.
Orchestrator — This is the most sophisticated pattern, and one being increasingly used in enterprise deployments. An orchestrator agent sits above the others, acting as a conductor, directing which subordinate agents run, in what sequence, with what inputs. Platforms such as LangGraph, AutoGen, CrewAI, and Microsoft Copilot all operate on this model. The appeal is centralized logic and reusability. The risk is equally centralized. The orchestrator is the single point of failure for the entire system — and the single highest-value target for an attacker.
A Real-World Architecture Walkthrough
Abstract components are easier to audit when you can trace them through something concrete. Here’s what a real request might look like moving through an enterprise agentic system and where, at each step, the audit questions live.
A sales manager types into a Copilot interface: “Summarize last quarter’s top accounts and send each account team a personalized update.”
Simple request. Here’s what actually happens.
Step 1: The request hits the Director agent. The Director agent (the orchestrator) receives the natural language instruction and takes ownership of the entire flow. It will coordinate every step that follows, and at the end, consolidate everything into a final response. This agent is the single most consequential component in the system. Audit question: Was this orchestrator configured and approved? Who can invoke it, and with what permissions?
Step 2: The Director agent gathers context before reasoning. Before any planning happens, the Director pulls in what it needs to think clearly. It performs a semantic search against the RAG knowledge base, including internal documents, past reports, account records, and retrieves relevant traces, decisions, and history from the memory store. Only once that context is assembled does it flow into the LLM. Audit question: What sources fed into this context? Who controls them, and could any of that content have been manipulated before it reached the model?
Step 3: The LLM reasons and produces an action plan. Now enriched with external context and memory, the LLM interprets the request, reasons through the steps required, and produces a plan. This is where the agent decides what needs to happen, and in what order. Audit question: Is this reasoning captured? Can the organization reconstruct why the model made the plan it did, or does the decision disappear after execution?
Step 4: The Director delegates to specialist agents. The plan gets split into discrete tasks and assigned to specialist agents with each one focused on a specific job, whether that’s analyzing data, drafting content, or preparing instructions for execution. No specialist acts on their own authority; they receive instructions and return results. Audit question: Is there a clear record of what each specialist was instructed to do? When something goes wrong, can you trace it back to the delegation decision that caused it?
Step 5: All actions flow through the MCP server. This is a critical architectural detail: the specialist agents don’t connect directly to tools. Every action is routed through a single MCP server, the sole action executor. This is both a control opportunity and a concentration risk. Audit question: Is the MCP server’s activity fully logged? Are the tools it can reach limited to what’s actually necessary? A misconfigured or compromised MCP server doesn’t just affect one agent — it affects all of them.
Step 6: The Director consolidates and returns the final answer. Tool responses flow back up through the MCP server to the specialist agents, and from there back to the Director, which unifies the results into a single coherent response and delivers it to the user. The loop is closed, but the audit trail should still be open. Audit question: Is there a complete, immutable record of the full cycle, from the original request to every context retrieval, reasoning step, delegation, action, and final output?
By the time the sales manager receives a response, their single request has touched a Director agent, a knowledge base, a memory store, an LLM, multiple specialist agents, an MCP server, and real business tools, each with its own permissions, risks, and audit implications.
The L1–L5 Framework
Ultimately, autonomy is the multiplier. It determines how much an agent can do without a human in the loop, how fast a mistake can propagate, and how much evidentiary infrastructure you need to audit it effectively. If you get this wrong, everything else is built on a shaky foundation.
That’s why locating every agent deployment on the autonomy scale must be the first step.
The five levels below are a risk-calibration tool. They tell you where a deployment sits today, what controls that level demands, and how much harder your job gets as that number climbs.
L1 — Assistant The agent suggests. It does not act. A human reads the output and decides what to do with it. Risk is low because the human remains the decision-maker and the executor. Audit scope is limited primarily to the quality and reliability of the recommendations being made.
L2 — Co-pilot The agent proposes actions and a human approves them before anything happens. The classic example is a drafting tool that writes an email and waits for you to hit send. Risk is low to medium because the human checkpoint is still intact, but auditors should verify that approvals are genuine reviews.
L3 — Bounded agent The agent executes on its own, but only within a defined perimeter. It can act, but its reach is deliberately limited. Risk is medium. The audit focus shifts to whether those boundaries are technically enforced, not just documented, and whether anyone is monitoring for attempts to operate outside them.
L4 — Autonomous agent The agent plans and executes without human approval, operating within budget and scope constraints that it manages itself. It decides, it acts, and it moves on. Risk is high. At this level, the absence of real-time monitoring isn’t a gap, it’s a liability. Auditors need to see robust observability, behavioral thresholds, and a tested kill switch before they can be satisfied that this deployment is under control.
L5 — Autonomous multi-agent The agent doesn’t just act, it coordinates other agents, chains decisions across systems, and operates continuously in production. A single instruction at the top of the chain can trigger a cascade of actions across the entire architecture before any human is aware. Risk is critical. At this level, the safeguards themselves are the audit. Human-in-the-loop checkpoints for irreversible actions, continuous behavioral monitoring, auditing agents watching the primary agents, and a documented emergency response plan are the baseline.

Greater agent autonomy requires additional controls and more robust safeguards, such as HITL, kill switches, continuous monitoring, and auditing agents. And the controls must scale with the level. What’s sufficient for an L2 co-pilot is inadequate for an L4 agent, let alone an L5 system operating at production speed.
The Takeaway
Agentic AI doesn’t just introduce new technology into the organization; it introduces new actors. These actors can perceive, reason, and decide. They can send emails, modify records, execute transactions, and coordinate other actors, all without waiting to be asked.
The anatomy is more complex than most organizations realize. The risks are more distributed than traditional audit frameworks were built to handle. And the speed at which these systems operate has already outpaced the annual audit cycle.
The auditors who get ahead of this won’t be the ones who understand AI best. They’ll be the ones who ask the right questions first and who have a working model of how agentic systems are built and deployed.
Next Article in the Series: How Auditing Agentic AI Is Different
Understanding how agentic AI is built is the necessary first step. The harder question is what changes when the subject of an audit can perceive, reason, decide, and act without a human in the loop.
The next article in this series confronts that question directly. It maps the five ways the audit role must evolve and introduces the seven specific challenges that make agentic AI uniquely difficult to audit, along with practical guidance on how to address each one.
About the Author
Esteban Farao is a Director of ERMProtect’s Cybersecurity Consulting Practice and a recognized leader in artificial intelligence and cybersecurity risk. With over 25 years of experience, he has directed enterprise AI initiatives spanning AI risk assessments, adversarial and AI-focused penetration testing, and organization-wide AI strategy and implementation. Esteban has led thousands of assessments, penetration tests, and forensic investigations for complex, high-risk organizations. A PCI Forensic Investigator and holder of multiple industry certifications, Esteban brings deep expertise in PCI compliance, regulatory frameworks, and breach investigations, working closely with organizations to strengthen security posture and navigate critical incidents.